

Homocédicité Qu'est-ce que l'importance et les exemples
- 726
- 144
- Jade Duval
La Homodécité Dans un modèle statistique prédictif, il se produit si dans tous les groupes de données d'une ou plusieurs observations, la variance du modèle par rapport aux variables explicatives (ou indépendantes) reste constante.
Un modèle de régression peut être homocédastique ou non, auquel cas nous parlons hétérocécité.
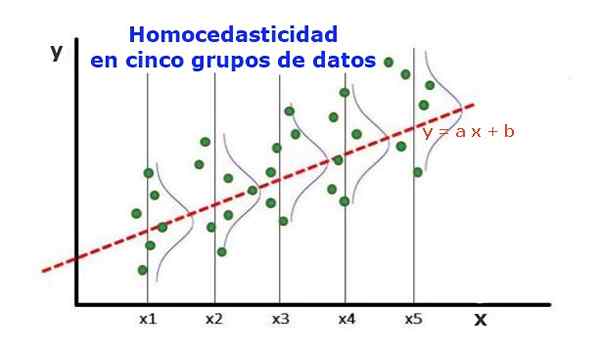
Figure 1. Cinq groupes de données et ajustement de régression de l'ensemble. La variance concernant la valeur prévue est la même dans chaque groupe. (Upav-bibliothèque.org) Un modèle de régression statistique de plusieurs variables indépendantes est appelée homocedastic, uniquement si la variance de l'erreur de variable prévue (ou l'écart type de la variable dépendante) reste uniforme pour différents groupes des variables explicatives ou indépendantes.
Dans les cinq groupes de données de la figure 1, la variance a été calculée dans chaque groupe, en ce qui concerne la valeur estimée par la régression, devenant la même dans chaque groupe. On suppose également que les données suivent la distribution normale.
Au niveau graphique, cela signifie que les points sont également dispersés ou dispersés autour de la valeur prévue par l'ajustement de régression, et que le modèle de régression a la même erreur et la même validité pour la plage de la variable explicative.
[TOC]
Importance de l'homocédicité
Pour illustrer l'importance de l'homocédasticité dans les statistiques prédictives, il est nécessaire de contraster avec le phénomène opposé, l'hétérogédicité.
Homocedasticité contre hétérocécité
Dans le cas de la figure 1, dans laquelle il y a l'homochédicité, il est réalisé que:
Var ((y1-y1); x1) ≈ var ((y2-y2); x2) ≈ ... var (y4-y4); x4)
Où var ((yi-ii); xi) représente la variance, la paire (xi, yi) représente un fait du groupe I, tandis que Yi est la valeur qui prédit la régression de la valeur xi moyenne du groupe. La variance des données du groupe I est calculée comme suit:
Var ((yi -ii); xi) = ∑j (yij - yi) ^ 2 / n
Au contraire, lorsque l'hétérocédité se produit, le modèle de régression peut ne pas être valable pour toute la région dans laquelle il a été calculé. La figure 2 montre un exemple de cette situation.
Peut vous servir: quels sont les angles alternatifs internes? (Avec des exercices)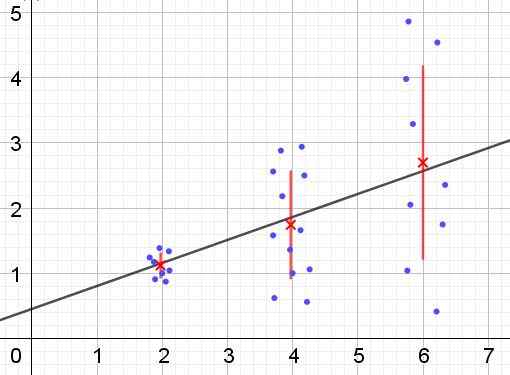 Figure 2. Groupe de données qui souffre d'hétérogédicité. (Élaboration propre)
Figure 2. Groupe de données qui souffre d'hétérogédicité. (Élaboration propre) Dans la figure 2, trois groupes de données et l'ensemble de l'ensemble sont représentés par une régression linéaire. Il convient de noter que les données du deuxième et du troisième groupe sont plus dispersées que dans le premier groupe. Le graphique de la figure 2 montre également la valeur moyenne de chaque groupe et sa barre d'erreur ± σ, étant l'écart type σ de chaque groupe de données. Il faut se rappeler que l'écart type σ est la racine carrée de la variance.
Es claro que en el caso de la heterocedasticidad, el error de la estimación por regresión es cambiante en el rango de valores de la variable explicativa o independiente, y en los intervalos donde este error es muy grande, la predicción por regresión es poco confiable o non applicable.
Dans un modèle de régression, des erreurs ou des déchets (y -y) doivent être distribués avec une variance égale (σ ^ 2) tout au long de l'intervalle de valeurs variables indépendantes. C'est pour cette raison qu'un bon modèle de régression (linéaire ou non linéaire) doit passer le test d'homocedasticité.
Tests d'homogédicité
Les points illustrés dans la figure 3 correspondent aux données d'une étude qui cherche une relation entre les prix (en dollars) des maisons en fonction de la taille ou de la zone en mètres carrés.
Le premier modèle qui est répété est celui d'une régression linéaire. En premier lieu, il est à noter que le coefficient de détermination R ^ 2 de l'ajustement est assez élevé (91%), il peut donc être pensé que l'ajustement est satisfaisant.
Cependant, deux régions peuvent être clairement distinguées du graphique de réglage. L'un d'eux, celui à droite verrouillé dans un ovale, rencontre l'homocedasticité, tandis que la région de la gauche n'a pas d'homocedasticité.
Peut vous servir: grade d'un polynôme: comment il est déterminé, exemples et exercicesCela signifie que la prédiction du modèle de régression est adéquate et fiable dans la plage entre 1800 m ^ 2 à 4800 m ^ 2 mais très inadéquate en dehors de cette région. Dans la zone hétérocédique non seulement, l'erreur est très grande, mais aussi les données semblent suivre une autre tendance différente de la proposition du modèle de régression linéaire.
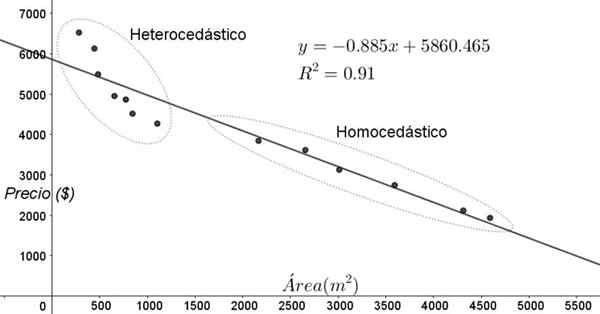 figure 3. Prix du logement vs zone et modèle prédictif par régression linéaire, montrant des zones d'homocédasticité et d'hétérogédicité. (Élaboration propre)
figure 3. Prix du logement vs zone et modèle prédictif par régression linéaire, montrant des zones d'homocédasticité et d'hétérogédicité. (Élaboration propre) Le graphique de dispersion des données est le test le plus simple et le plus visuel de leur homocedasticité, mais parfois il n'est pas aussi évident que dans l'exemple illustré à la figure 3, il est nécessaire de recourir à des graphiques avec des variables auxiliaires.
Variables standardisées
Dans le but de séparer les zones où l'homocedasticité est atteinte et dans laquelle non, les variables standardisées zres et zred sont introduites:
Zres = abs (y - y) / σ
Zpred = y / σ
Il convient de noter que ces variables dépendent du modèle de régression appliqué, car c'est la valeur de la prédiction de régression. Vous trouverez ci-dessous le graphique de dispersion ZRES vs Zred pour le même exemple:
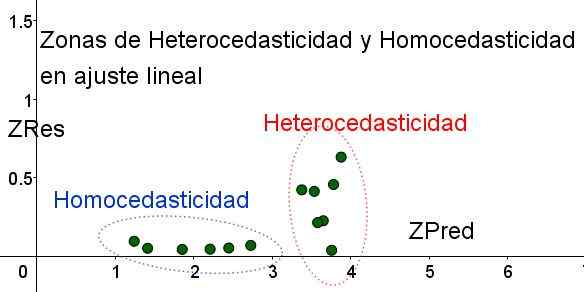 Figure 4. Il convient de noter que dans la zone d'homocedasticité, les zres restent uniformes et petits dans la région de prédiction (propre élaboration).
Figure 4. Il convient de noter que dans la zone d'homocedasticité, les zres restent uniformes et petits dans la région de prédiction (propre élaboration). Dans le graphique de la figure 4 avec les variables standardisées, la zone où l'erreur résiduelle est petite et uniforme est clairement séparée, par rapport à celle qui ne fait pas. Dans la première zone, l'homocedasticité est remplie tandis que l'erreur résiduelle est très variable et importante.
Un ajustement de régression est appliqué au même groupe de données 3. Le résultat est illustré dans la figure suivante:
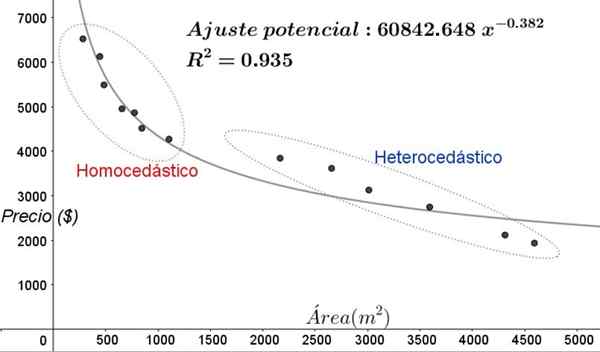 Figure 5. Nouvelles zones d'homocédasticité et d'hétérocédité dans l'ajustement des données avec un modèle de régression non linéaire. (Élaboration propre).
Figure 5. Nouvelles zones d'homocédasticité et d'hétérocédité dans l'ajustement des données avec un modèle de régression non linéaire. (Élaboration propre). Dans le graphique de la figure 5, les zones homocédique et hétérocédicastique doivent être clairement remarquées. Il convient également de noter que ces zones ont été échangées par rapport à celles qui ont été formées dans le modèle de réglage linéaire.
Peut vous servir: types d'angles, caractéristiques et exemplesDans le graphique de la figure 5, il est évident que même en cas de coefficient de détermination de l'ajustement assez élevé (93,5%), le modèle ne convient pas à l'intervalle entier de la variable explicative, car les données pour les valeurs de plus de 2000 m ^ 2 ont une hétérocédasticité.
Tests d'homocedasticité non
L'un des tests non enographiques les plus utilisés pour vérifier si l'homocedasticité est respectée ou non Test de Breusch-Pagan.
Tous les détails de ce test ne seront pas donnés dans cet article, mais ses caractéristiques fondamentales et les étapes de la même chose sont largement décrites:
- Le modèle de régression est appliqué aux n données N et la variance de celle-ci est calculée par rapport à la valeur estimée par le modèle σ ^ 2 = ∑j (yj - y) ^ 2 / n.
- Une nouvelle variable ε = ((yj - y) ^ 2) / (σ ^ 2) est définie
- Le même modèle de régression est appliqué à la nouvelle variable et ses nouveaux paramètres de régression sont calculés.
- La valeur critique du chi carré (χ ^ 2) est déterminée, ce qui représente la moitié de la somme des carrés nouveaux déchets dans la variable ε.
- Se usa la tabla de la distribución Chi cuadrado considerando en el eje x de la tabla el nivel de significancia (usualmente 5%) y el número de grados de libertad (#de variables de la regresión menos la unidad), para obtener el valor de le tableau.
- La valeur critique obtenue à l'étape 3 est comparée à la valeur trouvée dans le tableau (χ ^ 2).
- Si la valeur critique est inférieure à celle du tableau, vous avez l'hypothèse nulle: il y a l'homocédicité
- Si la valeur critique est supérieure à celle du tableau, vous avez l'hypothèse alternative: il n'y a pas d'homocedasticité.
La plupart des packages d'ordinateurs statistiques tels que: SPSS, Minitab, R, Python Pandas, SAS, Statgraphic et plusieurs autres intègrent le test d'homocedasticité de Breusch-Pagan. Un autre test pour vérifier l'uniformité de la variance Test de levène.
Les références
- Boîte, chasseur et chasseur. (1988) Statistiques pour les chercheurs. J'ai inversé les éditeurs.
- Johnston, J (1989). Méthodes d'économétrie, rédacteurs en chef de Vicens.
- Murillo et González (2000). Manuel de l'économie. Université de Las Palmas de Gran Canaria. Récupéré de: ULPGC.est.
- Wikipédia. Homodécité. Récupéré de: est.Wikipédia.com
- Wikipédia. Homoscédasticité. Récupéré de: dans.Wikipédia.com
- « Démonstration des permutations circulaires, exemples, exercices résolus
- Règle empirique Comment l'appliquer, à quoi sert-elle, les exercices résolus »