

Formule de fréquence absolue, calcul, distribution, exemple
- 1873
- 133
- Raphaël Meyer
La Frecuence absolue Il est défini comme le nombre de fois où les mêmes données sont répétées dans l'ensemble des observations d'une variable numérique. La somme de toutes les fréquences absolues équivaut à totaliser les données.
Lorsqu'il existe de nombreuses valeurs d'une variable statistique, il est pratique de les organiser correctement pour extraire des informations sur leur comportement. Ces informations sont données par des mesures de tendance centrale et des mesures de dispersion.
Figure 1. La fréquence absolue d'une observation statistique est la clé pour trouver la tendance qui suit l'ensemble de données Dans les calculs de ces mesures, les données sont représentées par la fréquence à laquelle elles apparaissent dans toutes les observations.
L'exemple suivant montre à quel point la fréquence absolue de chaque données est révélatrice. Au cours de la première moitié mai, il s'agissait de la taille des costumes de cocktails les plus vendus, d'un entrepôt de vêtements pour femmes bien connues:
8; dix; 8; 4; 6; dix; 12 14 12 16 8; dix; dix; 12 6; 6; 4; 8; 12 12 14 16 18 12 14 6; 4; dix; dix; 18
Combien de robes sont vendues dans une taille particulière, par exemple la taille 10? Les propriétaires sont intéressés à savoir faire des commandes.
La commande des données est plus facile à compter, il y a exactement 30 observations au total, que l'ordre du plus petit au plus élevé est comme ceci:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; dix; dix; dix; dix; dix; dix; 12 12 12 12 12 12; 14; 14 14; 16; 16; 18 18
Et maintenant, il est évident que la taille 10 est répétée 6 fois, donc sa fréquence absolue est égale à 6. La même procédure est effectuée pour découvrir la fréquence absolue des tailles restantes.
[TOC]
Formules
La fréquence absolue, désignée fToi, Il est égal au nombre de fois comme une certaine valeur xToi est dans le groupe d'observations.
En supposant que les observations totales sont de n valeurs, la somme de toutes les fréquences absolues doit être égale audit numéro:
Peut vous servir: Papomudas∑FToi = F1 + F2 + F3 +… Fn = N
Autres fréquences
Si chaque valeur de fToi Il est divisé par le nombre total de données n, vous avez le fréquence relative Fr de valeur xToi:
Fr = FToi / N
Les fréquences relatives sont des valeurs entre 0 et 1, car n est toujours supérieur à tout FToi, Mais la somme doit être égale à 1.
Multipliant par 100 à chaque valeur de fr tu as le Fréquence pour pourcentage relatif, dont la somme est à 100%:
Fréquence de pourcentage relatif = (FToi / N) x 100%
Il est également important fréquence accumulée FToi Jusqu'à une certaine observation, c'est la somme de toutes les fréquences absolues jusqu'à ce que cette observation inclusive:
FToi = F1 + F2 + F3 +… FToi
Si la fréquence accumulée est divisée par le nombre total de données n, vous avez le fréquence relative accumulée, qui se multiplient pour 100 résultats dans le pourcentage de fréquence relatif accumulé.
Comment obtenir la fréquence absolue?
Pour trouver la fréquence absolue d'une certaine valeur qui appartient à un ensemble de données, toutes sont organisées du moins au plus grand et la valeur est comptée.
Dans l'exemple des tailles des robes, la fréquence absolue de la taille 4 est de 3 robes, c'est-à-dire f1 = 3. Pour la taille 6, 4 robes ont été vendues: F2 = 4. En taille 8 4, des robes ont également été vendues, f3 = 4 et ainsi de suite.
Tabulation
Les résultats totaux peuvent être représentés dans un tableau qui montre les fréquences absolues de chacun:
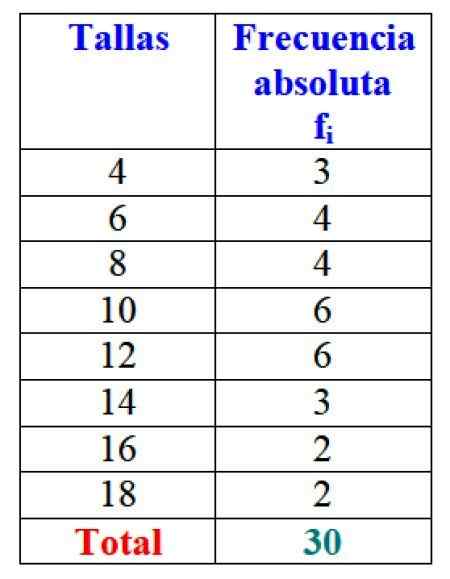 Figure 2. Tableau qui représente la variable "vendeurs" et les fréquences absolues respectives. Source: F. Zapata.
Figure 2. Tableau qui représente la variable "vendeurs" et les fréquences absolues respectives. Source: F. Zapata. De toute évidence, il est avantageux de commander les informations et de pouvoir y accéder, au lieu de travailler avec des données lâches.
Important: Notez qu'en ajoutant toutes les valeurs de la colonne FToi Le nombre total de données est toujours obtenu. Sinon, la comptabilité doit être examinée, car il y a une erreur.
Table de fréquence étendue
Le tableau précédent peut être étendu en ajoutant les autres types de fréquence dans les colonnes successives à droite:
Peut vous servir: homocedasticité: ce qui est, l'importance et les exemples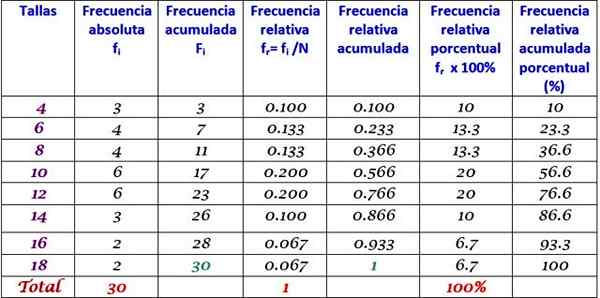
Distribution de fréquence
La distribution des fréquences est le résultat de l'organisation des données en termes de fréquences. Lorsque vous travaillez avec de nombreuses données, il est pratique de les regrouper en catégories, intervalles ou classes, chacun avec leurs fréquences respectives: absolue, relative, accumulée et pourcentage.
L'objectif de les faire est d'accéder plus facilement aux informations que les données contient, ainsi que de les interpréter correctement, ce qui n'est pas possible lorsqu'ils sont présentés sans commande.
Dans l'exemple des tailles, les données ne sont pas regroupées, car elles ne sont pas trop de tailles et peuvent facilement être manipulées et comptées. Les variables qualitatives peuvent également être travaillées de cette manière, mais lorsque les données sont très nombreuses, elles fonctionnent mieux les regrouper en classe.
Distribution de fréquence pour les données groupées
Pour regrouper les données dans des classes de taille égale, les éléments suivants doivent être pris en compte:
-Taille, largeur ou amplitude de la classe: C'est la différence entre la plus grande valeur de la classe et le mineur.
La taille des classes est décidée en divisant la plage R par le nombre de classes à considérer. La plage est la différence entre la valeur maximale des données et le mineur, comme ceci:
Taille de classe = plage / nombre de classes.
-Limite de classe: intervalle qui va de la limite inférieure à la limite supérieure de la classe.
-Marque de classe: C'est le milieu de l'intervalle, qui est considéré comme représentatif de la classe. Il est calculé avec la semi-limite de la limite supérieure et la limite inférieure de la classe.
-Nombre de classes: La formule Sturges peut être utilisée:
Classes = 1 + 3 322 log n
Où n est le nombre de classes. Comme c'est généralement un nombre décimal, les éléments suivants sont arrondis.
Exemple
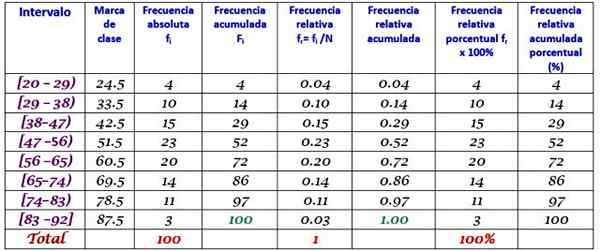
Une grande machine d'usine est hors opération, car elle a des échecs récurrents. Les périodes consécutives d'inactivité en minutes, de ladite machine, sont enregistrées ci-dessous, avec un total de 100 données:
Il peut vous servir: Probabilité de fréquence: concept, comment il est calculé et des exemples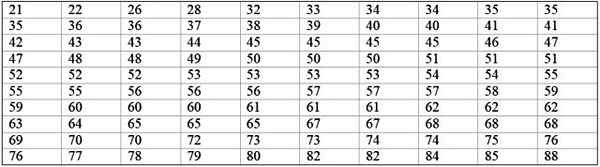
Le nombre de classes est d'abord déterminé:
Classes = 1 + 3 322 log n = 1 + 3.32 log 100 = 7.64 ≈ 8
Taille de classe = plage / nombre de classes = (88-21) / 8 = 8.375
C'est aussi un numéro décimal, il faut donc 9 comme taille de classe.
La marque de classe est la moyenne entre la limite supérieure et inférieure de la classe, par exemple pour la classe [20-29) Il y a une marque de:
Marque de classe = (29 + 20) / 2 = 24.5
Procéder à la même manière pour trouver les marques de classe des intervalles restants.
Exercice résolu
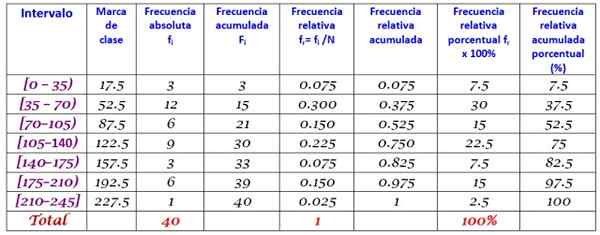
40 jeunes ont indiqué que le temps en procès-verbal qui est passé sur Internet dimanche dernier était le prochain, commandé de plus en plus:
0; 12 vingt; 35; 35; 38; 40; Quatre cinq; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200;; 220.
Il est demandé de construire la distribution de fréquence de ces données.
Solution
Le rang r de l'ensemble de n = 40 données est:
R = 220 - 0 = 220
L'application de la formule Sturges pour déterminer le nombre de classes donne le résultat suivant:
Classes = 1 + 3 322 log n = 1 + 3.32 log 40 = 6.3
Comme c'est une décimale, l'ensemble immédiat est de 7, donc les données sont regroupées en 7 classes. Chaque classe a une largeur de:
Taille de classe = plage / nombre de classes = 220/7 = 31.4
Une valeur proche et ronde est de 35, donc une largeur de classe de 35 est choisie.
Les marques de classe sont calculées en moyenne de la limite supérieure et inférieure de chaque intervalle, par exemple, pour l'intervalle [0,35):
Marque de classe = (0 + 35) / 2 = 17.5
Nous procédons de la même manière avec les cours restants.
Enfin, les fréquences sont calculées en fonction de la procédure décrite ci-dessus, entraînant la distribution suivante:
Les références
- Berenson, M. 1985. Statistiques pour l'administration et l'économie. Inter-américain s.POUR.
- Devore, J. 2012. Probabilité et statistiques pour l'ingénierie et la science. 8e. Édition. Cengage.
- Levin, R. 1988. Statistiques pour les administrateurs. 2e. Édition. Prentice Hall.
- Spiegel, m. 2009. Statistiques. Série Schaum. 4 ta. Édition. McGraw Hill.
- Walpole, R. 2007. Probabilité et statistiques pour l'ingénierie et la science. Pearson.