

Données non groupées et exercice résolu

- 3534
- 859
- Raphaël Meyer
Les Données non groupées Ce sont ceux qui, obtenus d'une étude, ne sont pas encore organisés par des classes. Lorsqu'il s'agit d'un nombre gérable de données, généralement 20 ou moins, et qu'il y a peu de données différentes, elles peuvent être traitées comme non regroupées et en extraire des informations précieuses.
Les données non groupées proviennent de l'enquête ou de l'étude réalisée pour les obtenir et donc manquer de traitement. Regardons quelques exemples:
Figure 1. Les données non groupées proviennent directement d'une étude et n'ont pas été classées. Source: pxhere. -Résultats d'un examen CI du coefficient intellectuel à 20 étudiants aléatoires d'une université. Les données obtenues étaient les suivantes:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112,106
-Âgés de 20 employés d'une cafétéria très populaire:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
-Les notes finales moyennes de 10 élèves d'un cours de mathématiques:
3.2; 3.1; 2,4; 4.0; 3.5; 3.0; 3.5; 3.8; 4.2; 4.9
[TOC]
Propriétés de données
Il existe trois propriétés importantes qui caractérisent un ensemble de données statistiques sont regroupées ou non, qui sont:
-Position, qui est la tendance des données à être regroupées autour de certaines valeurs.
-Dispersion, Un indicatif de la façon dont les données sont dispersées ou diffusées sur une certaine valeur.
-Forme, Il se réfère à la manière dont les données sont distribuées, ce qui peut être vu lorsqu'un graphique d'entre eux est construit. Il existe des courbes très symétriques et également biaisées, à gauche ou à droite d'une certaine valeur centrale.
Pour chacune de ces propriétés, il existe un certain nombre de mesures qui les décrivent. Une fois obtenus, ils nous donnent un panorama de comportement des données:
-Les mesures de position les plus utilisées sont la moyenne arithmétique ou tout simplement moyenne, médiane et mode.
-Dans la dispersion, la plage, la variance et l'écart type sont fréquemment utilisés, mais ils ne sont pas les seules mesures de dispersion.
Peut vous servir: homotecia-Et pour déterminer la forme, la moyenne et la médiane sont comparées par le biais, comme on le verra sous peu.
Calcul de la moyenne, de la médiane et de la mode
-La moyenne arithmétique, Également connu sous le nom de moyenne et indiqué sous le nom de X, il est calculé comme suit:
X = (x1 + X2 + X3 +... Xn) / n
Où x1, X2,.. . Xn, sont les données et n est le total d'entre eux. En résumé de la somme, il y a:

-La médiane C'est la valeur qui apparaît au milieu d'une succession de données ordonnée, donc pour l'obtenir, il est nécessaire de commander d'abord les données.
Si le nombre d'observations est étrange, il n'y a aucun problème à trouver le point médian de l'ensemble, mais si nous avons une paire de données, les deux données centrales sont recherchées et moyennées.
-Mode C'est la valeur la plus courante observée dans l'ensemble de données. Il n'existe pas toujours, car il est possible qu'aucune valeur ne soit répétée plus fréquemment qu'un autre. Il pourrait également y avoir deux données avec une fréquence égale, auquel cas il est question d'une distribution bi-modale.
Contrairement aux deux mesures précédentes, la mode peut être utilisée avec des données qualitatives.
Voyons comment ces mesures de position sont calculées avec un exemple:
Exemple résolu
Supposons que vous souhaitiez déterminer la moyenne arithmétique, la médiane et la mode dans l'exemple proposé au début: l'âge de 20 employés d'une cafétéria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
La moitié Il est calculé simplement en ajoutant toutes les valeurs et en divisant par n = 20, qui est le nombre total de données. De cette manière:
Peut vous servir: Relations de proportionnalité: concept, exemples et exercicesX = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22.3 ans.
Pour trouver le médian Il est nécessaire de commander d'abord l'ensemble de données:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Tout comme quelques données, les deux données centrales, mises en évidence en gras, sont prises et moyennes. Parce que les deux ont 22 ans, la médiane est de 22 ans.
Finalement, le mode C'est le fait qui est répété le plus ou que la fréquence est plus grande, étant ces 22 ans.
Gamme, variance, écart-type et biais
La gamme est simplement la différence entre le majeur et le moindre des données et permet à leur variabilité d'apprécier rapidement. Mais à part, il existe d'autres mesures de dispersion qui offrent plus d'informations sur la distribution des données.
Variance et écart-type
La variance est indiquée comme S et est calculée par expression:
^2n)
^2n-1)
Ensuite, pour interpréter à juste titre les résultats, l'écart-type tel que la racine carrée de la variance, ou aussi la quasi-écarté standard est définie, qui est la racine carrée de la quasivariance:
^2n)
^2n-1) Biais
Biais
C'est la comparaison entre le X moyen et le MED médian:
-Oui Med = Media X: Les données sont symétriques.
-Quand x> med: biaisé vers la droite.
-Et si x < Med: los datos sesgan hacia la izquierda.
Exercice résolu
Trouvez la moyenne, la médiane, la mode, le rang, la variance, l'écart-type et le biais pour les résultats d'un examen du coefficient intellectuel de 20 étudiants d'une université:
Peut vous servir: fonctions mathématiques119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Solution
Nous commanderons les données, car il sera nécessaire de trouver la médiane.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
Et nous les mettrons dans une table comme suit, pour faciliter les calculs. La deuxième colonne intitulée "Accumulé" est la somme des données correspondantes plus la précédente.
Cette colonne trouvera facilement la moyenne, divisant le dernier accumulé entre le nombre total de données, comme on le voit à la fin de la colonne «accumulée»:
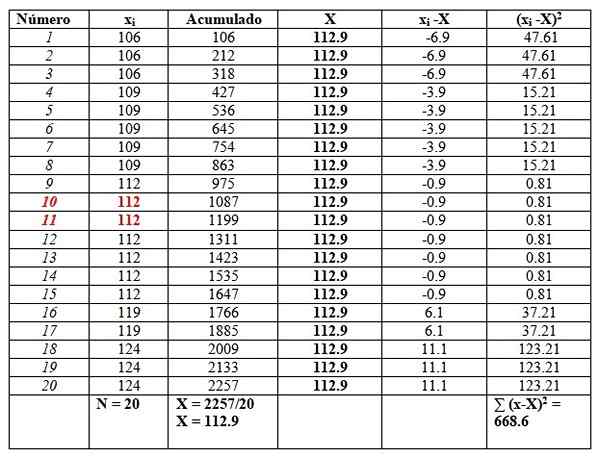
X = 112.9
La médiane est la moyenne des données centrales mises en évidence en rouge: numéro 10 et numéro 11. Tout comme le même, la médiane est 112.
Enfin, la mode est la valeur la plus répétée et est de 112, avec 7 répétitions.
Quant aux mesures de dispersion, la plage est:
124-106 = 18.
La variance est obtenue en divisant le résultat final de la colonne de droite entre n:
S = 668.6/20 = 33.42
Dans ce cas, l'écart type est la racine carrée de la variance: √33.42 = 5.8.
D'un autre côté, les valeurs de la quasivarité et l'écart type quasi sont:
sc= 668.6/19 = 35.2
Quasi-déviation standard = √35.2 = 5.9
Enfin, le biais est légèrement à droite, car la moyenne 112.9 est supérieur à la médiane 112.
Les références
- Berenson, M. 1985. Statistiques pour l'administration et l'économie. Inter-américain s.POUR.
- Canavos, g. 1988. Probabilité et statistiques: applications et méthodes. McGraw Hill.
- Devore, J. 2012. Probabilité et statistiques pour l'ingénierie et la science. 8e. Édition. Cengage.
- Levin, R. 1988. Statistiques pour les administrateurs. 2e. Édition. Prentice Hall.
- Walpole, R. 2007. Probabilité et statistiques pour l'ingénierie et la science. Pearson.
- « Degrés de liberté Comment les calculer, les types, les exemples
- Types d'axiomes de probabilité, explication, exemples, exercices »