

Codon
- 632
- 9
- Mlle Ambre Dumont
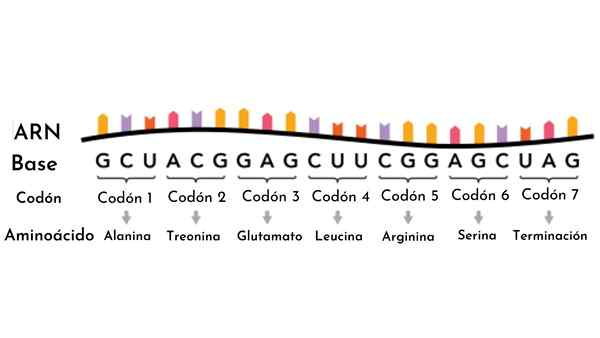
Un codon est un triplet nucléotidique qui code pour les acides aminés dans le code génétique Qu'est-ce qu'un codon?
UN codon Il s'agit de chacune des 64 combinaisons possibles de trois nucléotides, basés sur les quatre qui composent les acides nucléiques. Autrement dit, à partir de combinaisons des quatre nucléotides, des blocs de trois "lettres" ou des triplets sont construits.
Ce sont les désoxyribonucléotides avec les bases d'adénine, de guanine, de timin et de cytosine dans l'ADN. Dans l'ARN, ce sont les ribonucléotides avec les bases d'azote d'adénine, de guanine, d'uracile et de cytosine.
Le concept de codon est appliqué uniquement aux gènes qu'ils codent pour les protéines. Le message codé dans l'ADN sera lu en trois blocs de lettres une fois que les informations de votre messager seront traitées.
Le codon, en bref, est l'unité de codage de base pour les gènes qui sont traduits.
Codons et acides aminés
Si pour chaque position en trois lettres, nous avons quatre possibilités, le produit 4 x 4 x 4 nous fournit 64 combinaisons possibles. Chacun de ces codons correspond à un acide aminé particulier, sauf trois qui fonctionnent comme des codons de lecture.
La conversion d'un message codifié avec des bases d'azote en un acide nucléique avec des acides aminés dans un peptide est appelée traduction. La molécule qui mobilise le message de l'ADN au site de traduction est appelée ARN messager.
Un triplet d'un ARN messager est un codon dont la traduction sera effectuée dans les ribosomes. Les petites molécules d'adaptateur qui changent le langage nucléotidique en celles des acides aminés dans les ribosomes sont les ARN de transfert.
Message, messagers et traduction
Un message codant pour la protéine consiste en un arrangement nucléotidique linéaire qui est un multiple de trois. Le message est transporté par un ARN que nous appelons Messenger (RNM).
Peut vous servir: dihibridismeDans les organismes cellulaires, tous les ARN surgissent par transcription du gène codé dans leur ADN respectif. C'est-à-dire que les gènes codants pour les protéines sont écrits en ADN en langage ADN.

Cependant, cela ne signifie pas que cette règle des trois strictes dans l'ADN est remplie. Lorsqu'il est transcrit à partir de l'ADN, le message est maintenant écrit en langue ARN.
Le RNM se compose d'une molécule avec le message du gène, flanqué des deux côtés par des régions non codantes. Certaines modifications post-transcriptales, telles que l'épissage, par exemple, permettent de générer un message qui répond à la règle.
Si cette règle des trois ne semblait pas être remplie dans l'ADN, l'épissage est restauré.
Le RNM est transporté sur le site où résident les ribosomes, et ici le messager dirige la traduction du message à la langue protéique.
Dans le cas le plus simple, la protéine (ou peptide) aura un certain nombre d'acides aminés égaux à un tiers des lettres du message sans trois d'entre elles. C'est-à-dire égal au nombre de codons du messager sauf l'un de la résiliation.
Message génétique
Un message génétique d'un gène qui codifie pour les protéines commence généralement par un codon qui se traduit par la méthodin d'acide aminé (Codón Aug, dans l'ARN).
Ensuite, un nombre caractéristique de codons se poursuit dans une longueur et une séquence linéaires spécifiques, et se termine par un codon de terminaison. Le codon de terminaison peut être l'une des codons d'opale (UGA), Amber (UAG) ou OCRE (UAA).
Cela n'a pas d'équivalent en langue d'acide aminé et, par conséquent, ni d'un ARN de transfert correspondant.
Il peut vous servir: Hollandic Héritage: caractéristiques, fonctions des gènes, dégénérescenceCependant, dans certains organismes, le codon UGA permet l'incorporation de la sélénocystéine d'acides aminés modifiée. Dans d'autres, le codon UAG permet l'incorporation de la pyrolisine d'acide aminé.
L'ARN messager est complexe avec les ribosomes, et l'initiation de la traduction permet l'incorporation d'une méthodine initiale. Si le processus réussit, la protéine sera allongée (allongement) dans la mesure où chaque ARNT donne l'acide aminé correspondant guidé par le messager.
Pour atteindre le codon de terminaison, l'incorporation d'acides aminés s'arrête, la traduction se termine et le peptide synthétisé est libéré.
Codons et anticodones
Bien qu'il s'agisse d'une simplification d'un processus beaucoup plus complexe, l'interaction Codon-IntoDon soutient l'hypothèse de traduction par complémentarité.
Selon cela, pour chaque codon d'un messager, l'interaction avec un ARNT particulier sera dictée par la complémentarité avec les bases d'Anticodón.
L'anticodon est la séquence de trois nucléotides (triplet) présents dans la base circulaire d'un ARNT typique. Chaque ARNT spécifique peut être chargé d'un acide aminé particulier, qui sera toujours le même.
De cette façon, lorsqu'un anticodon est reconnu, le messager indique au ribosome que l'acide aminé que l'ARNT porte pour lequel il est complémentaire dans ce fragment.
L'ARNT agit donc, comme un adaptateur qui permet de vérifier la traduction effectuée par le ribosome. Cet adaptateur, en étapes de lecture du codon à trois lettres, permet l'incorporation linéaire d'acides aminés qui constitue enfin le message traduit.
La dégénérescence du code génétique
Correspondance du codon: l'acide aminé est connu en biologie sous le nom de code génétique. Ce code comprend également les trois codons de terminaison de traduction.
Il peut vous servir: qu'est-ce qu'une apomorphie? (Avec des exemples)Il y a 20 acides aminés essentiels, mais, à son tour, il y a 64 codons disponibles pour la conversion. Si nous éliminons les trois codons de terminaison, nous avons encore 61 pour coder les acides aminés.
La métitionine n'est codifiée que par le codon AUG, qui est de démarrer le codon, mais aussi de cet acide aminé particulier ailleurs du message (gène).
Cela nous amène à 19 acides aminés codés par les 60 codons restants. De nombreux acides aminés sont codés par un seul codon. Cependant, il existe d'autres acides aminés codés par plus d'un codon. Ce manque de relation entre le codon et l'acide aminé est ce que nous appelons la dégénérescence du code génétique.
Organites
Enfin, le code génétique est partiellement universel. Dans les eucaryotes, il existe d'autres organites (dérivés évolutives des bactéries) où une traduction différente est vérifiée que celle vérifiée dans le cytoplasme.
Ces organites avec leur propre génome (et traduction) sont des chloroplastes et des mitochondries. Les codes génétiques des chloroplastes, des mitochondries, des eucaryotes et des nucléoïdes bactériens ne sont pas exactement identiques.
Cependant, dans chaque groupe, c'est universel. Par exemple, un gène végétal qui se clonait et se traduit par une cellule animale donnera naissance à un peptide avec la même séquence linéaire d'acides aminés qui aurait dû être traduite dans la plante d'origine.
Les références
- Brooker, R. J. Génétique: analyse et principes. McGraw-Hill Higher, Education, New York.
- Griffiths, un. J. F., Wessler, R., Carroll, S. B., Doebley, J. Une introduction à l'analyse génétique. New York.
- Koonin, E. V., Novozhilov, un. S. Origine et évolution du code génétique universel. Revue annuelle de la génétique.